
ご無沙汰です。最近は11/8のエクトラ自主企画に向けて、ソワソワしております。子どもの寝かしつけが終わらないとギター弾けないんですが、最近寝付きが悪いです(怒)。
さて、タイトルについて。
2018年に独自ドメインを取得してこのワードプレスに引っ越してきましたが、以前は無料のエキサイトブログで書いていました。
そもそも日記書くのが好きで、もうサービス終了してますけど魔法のiらんどに始まり、モバイルスペース、その他様々なネット上の媒体に駄文を書き殴ってきました。
エキサイトブログもいつサービス終了するかわからないし、独自ドメインのサイト(ここ)があるならいつかデータ移しておきたいなと思いつつも、気づけば数年経っていました。
そもそも当時は完全に自分のための日記のつもりで、おそらく1週間に1記事以上の頻度で書いてて10年弱あるから、相当な記事数(実際685記事だった)だと思うので、手動では無理だろなーと。
しかし先日、ある件をきっかけに記憶を辿りに久々に自分のエキサイトブログを覗いたんですが、「chatGPTあるし、今ならできるかも」ということで重い腰を上げました。
初めてPython使ってみた

chatGPTに「エキサイトブログに過去の日記がある。今はドメイン取ってワードプレスにブログがあるんだけど、コピーする簡単な方法ない?」と聞いたら、「Pythonを使ったらできるでー」とのこと。
Python、存在は知っていたし、最近は仕事でもGoogleのGASをchatGPTを駆使してイジりまくっているのでイケるだろうということで、採用。
chatGPTに「エキサイトブログ記事一覧からワードプレスにインポートできるWXRファイルを生成するPythonのスクリプト」を作ってもらい、
実際のページの構造(HTML)などを見てもらって試行錯誤した結果、
- タイトル
- 投稿した日時
- 本文
- 画像
まで取り込めるWXRファイルを生成することに成功。
以下にchatGPTに一般化してもらったコードを乗せておきます。(もちろん転載元がエキサイトブログでなくても、chatGPTなどのAIに投げればいい感じに変換してくれると思います)
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""Exblog (excite.co.jp) -> WordPress (WXR 1.2) exporter- Crawl an Excite Blog (e.g., https://foo.exblog.jp/) and export posts to a WXR file.- Grabs: title / HTML content / published datetime / permalink (as GUID)- Avoids picking "hotentry" list cards; follows canonical; follows numeric post URLs.- Cleans duplicate in-body title and trailing "by username | YYYY-MM-DD HH:MM".- Writes BOM-less UTF-8 XML that Edge/WordPress can read cleanly.- Optionally bumps post dates by N seconds to avoid WP importer dedup skipping.Usage examples: python exblog_to_wxr.py --start-url https://example.exblog.jp/12345678/ --out test_one.xml --max-posts 1 --no-crawl python exblog_to_wxr.py --start-url https://example.exblog.jp/ --out export.xml --max-posts 10000 python exblog_to_wxr.py --start-url https://example.exblog.jp/ --out export.xml --date-bump-seconds 1Requirements: pip install requests beautifulsoup4 python-dateutil lxml"""from __future__ import annotationsimport reimport timeimport htmlimport hashlibimport argparsefrom datetime import datetime, timezone, timedeltafrom urllib.parse import urljoin, urlparseimport requestsfrom bs4 import BeautifulSoupfrom dateutil import parser as dateparser# ---------------------------------# Config (tuned for exblog)# ---------------------------------CONFIG = { # Content candidates (prioritized). Must be OUTSIDE ".hotentry". "content_selectors": [ 'div#main div.mainTxt', 'div#main div.txt', 'div#main article', 'div.mainTxt', 'div[itemprop="articleBody"]', 'div[class*="entry-body"]', 'div[class*="post-content"]', 'div[class*="article"]', 'div[class*="entry"]', 'div[class*="post"]', 'article', ], # Title candidates (prioritized). Includes og:title meta. "title_selectors": [ 'div#main div.post_head h2', 'div.post_head h2', 'div#main h2.ttl', 'h2.ttl', 'meta[property="og:title"]', 'meta[name="twitter:title"]', 'h1[class*="entry-title"]', 'h1.post-title', 'h1', 'h2', ], # Date candidates (prioritized). "date_selectors": [ 'p.tail a', 'span.TIME a', 'time[datetime]', 'time', 'meta[property="article:published_time"]', 'meta[name="pubdate"]', 'meta[property="og:updated_time"]', 'meta[property="og:published_time"]', ], # Allow only exblog domain "allowed_url_pattern": re.compile(r"^https?://[^/]*exblog\.jp/.*", re.I), # Deny noisy areas "deny_url_patterns": [ re.compile(r"/image/", re.I), re.compile(r"/theme-", re.I), re.compile(r"/tags?/", re.I), re.compile(r"/atom\.xml|/index\.xml", re.I), re.compile(r"/genre/|/platinum/|/blogtheme/|/official/|/new/pr/|/campaign/|/paywall/|/agreement/|/gallery/|/push/settings/|/advance/", re.I), ], # Numeric post URLs: /12345678/ "post_url_pattern": re.compile(r"/\d{6,}/?$", re.I), # Archive pagination etc. "archive_url_patterns": [ re.compile(r"/page/\d+/?$", re.I), re.compile(r"[?&]page=\d+", re.I), re.compile(r"^https?://[^/]*exblog\.jp/?$", re.I), ], # Request tuning "request_timeout": 20, "sleep_sec": 0.2, # WXR channel defaults (edit if you want) "base_site_url": "https://example.com", "base_blog_url": "https://example.com", "author_login": "admin", "author_email": "admin@example.com",}HEADERS = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}# ---------------------------------# HTTP helpers# ---------------------------------def fetch(url: str) -> requests.Response: for pat in CONFIG["deny_url_patterns"]: if pat.search(url):raise RuntimeError(f"Denied by pattern: {url}") for _ in range(3): try:r = requests.get(url, headers=HEADERS, timeout=CONFIG["request_timeout"])if r.status_code == 200: return rif 400 <= r.status_code < 500: raise RuntimeError(f"Failed to fetch ({r.status_code}): {url}") except requests.RequestException:time.sleep(0.5) raise RuntimeError(f"Failed to fetch: {url}")# ---------------------------------# Extract helpers# ---------------------------------def extract_first(soup: BeautifulSoup, selectors: list[str]): for sel in selectors: el = soup.select_one(sel) if not el:continue if el.name == "meta":if el.get("content"): return el # meta handled by caller else:return el return Nonedef is_inside_hotentry(el) -> bool: p = el while p is not None: if getattr(p, "get", None) and "class" in p.attrs:classes = p.get("class", [])if any("hotentry" in c for c in classes): return True p = p.parent return Falsedef find_article_content(soup: BeautifulSoup): for sel in CONFIG["content_selectors"]: el = soup.select_one(sel) if el and not is_inside_hotentry(el):# skip tiny fragments (likely list cards)if len(el.get_text(strip=True)) < 20 and len(str(el)) < 200: continuereturn el return Nonedef normalize_html(html_text: str) -> str: soup = BeautifulSoup(html_text, "lxml") for tag in soup(["script", "noscript", "style"]): tag.decompose() for he in soup.select(".hotentry"): he.decompose() return str(soup)def slugify(text: str, length: int = 80) -> str: base = re.sub(r"\s+", "-", text.strip()) base = re.sub(r"[^\w\-]", "", base) base = base.strip("-")[:length] return base.lower() or hashlib.md5(text.encode()).hexdigest()[:12]def parse_date_robust(soup: BeautifulSoup) -> datetime: # Try selectors for sel in CONFIG["date_selectors"]: el = soup.select_one(sel) if not el:continue val = el.get("datetime") or el.get("content") or el.get_text(strip=True) if val:try: dt = dateparser.parse(val) if not dt.tzinfo: dt = dt.replace(tzinfo=timezone.utc) else: dt = dt.astimezone(timezone.utc) return dtexcept Exception: pass # Fallback: scan plain text for YYYY-MM-DD HH:MM txt = soup.get_text(" ", strip=True) m = re.search(r"(\d{4}-\d{2}-\d{2}[ T]\d{2}:\d{2})", txt) if m: try:dt = dateparser.parse(m.group(1))if not dt.tzinfo: dt = dt.replace(tzinfo=timezone.utc)else: dt = dt.astimezone(timezone.utc)return dt except Exception:pass return datetime.now(timezone.utc)def resolve_canonical(soup: BeautifulSoup, base_url: str) -> str | None: can = soup.select_one('link[rel="canonical"][href]') if can and can.get("href"): url = urljoin(base_url, can["href"]).split("#")[0] if CONFIG["allowed_url_pattern"].match(url):return url return Nonedef extract_title_robust(soup: BeautifulSoup) -> str | None: el = extract_first(soup, CONFIG["title_selectors"]) if not el: return None if el.name == "meta": return el.get("content", None) return el.get_text(strip=True)# ---------------------------------# Content cleaning: drop duplicate title & trailing footer "by X | yyyy-mm-dd hh:mm"# ---------------------------------FOOTER_PATTERNS = [ re.compile(r"^\s*by\s+\S+\s*\|\s*\d{4}-\d{2}-\d{2}\s+\d{2}:\d{2}\s*$"), re.compile(r"^\s*by\s+\S+\s*$"), re.compile(r"^\s*\d{4}-\d{2}-\d{2}\s+\d{2}:\d{2}\s*$"),]def strip_title_and_footer(content_html: str, title_text: str | None) -> str: soup = BeautifulSoup(content_html, "lxml") # Remove duplicated heading equal to title (only near the top; safe) if title_text: norm_t = title_text.replace(" "," ").strip() for tag in soup.find_all(["h1","h2","h3","p","div"]):t = tag.get_text(strip=True)if not t: continueif t == norm_t or t.replace(" "," ").strip() == norm_t: tag.decompose() break for sel in ["div.post_head", "h2.ttl"]:for el in soup.select(sel): el.decompose() # Remove common footer containers for sel in ["p.tail", "span.TIME", "div.post_foot", "div.posted", "div.posted_by"]: for el in soup.select(sel):el.decompose() # Remove single-line blocks at the very end that match footer patterns blocks = list(soup.find_all(["p","div","span","li","blockquote"], recursive=True)) for el in reversed(blocks[-10:]): # check a handful from the tail txt = el.get_text("\n", strip=True) if not txt:continue lines = [ln.strip() for ln in txt.splitlines() if ln.strip()] if len(lines) == 1 and any(pat.match(lines[0]) for pat in FOOTER_PATTERNS):el.decompose()break return str(soup)# ---------------------------------# Post extraction (with follow)# ---------------------------------def extract_post_or_follow(url: str, html_text: str) -> dict | None: soup = BeautifulSoup(html_text, "lxml") # Prefer canonical URL content can = resolve_canonical(soup, url) if can and can.rstrip("/") != url.rstrip("/"): try:r = fetch(can)soup = BeautifulSoup(r.text, "lxml")url = can except Exception as e:print(f"[WARN] canonical fetch failed: {can} ({e})") content_el = find_article_content(soup) if content_el: title = extract_title_robust(soup) or url dt = parse_date_robust(soup) cleaned = strip_title_and_footer(normalize_html(str(content_el)), title) return {"title": title,"content_html": cleaned,"date_utc": dt,"slug": slugify(title),"link": url, } # Follow numeric post URL candidates for a in soup.select('a[href]'): cand = urljoin(url, a["href"]).split("#")[0] if CONFIG["post_url_pattern"].search(cand):try: r2 = fetch(cand) return extract_post_or_follow(cand, r2.text)except Exception as e: print(f"[WARN] follow failed: {cand} ({e})") continue return None# ---------------------------------# Crawler# ---------------------------------def is_internal_and_allowed(base_netloc: str, href: str) -> bool: try: if not href:return False parsed = urlparse(href) if not parsed.scheme:url_candidate = hrefnetloc_ok = True else:url_candidate = hrefnetloc_ok = (parsed.netloc == base_netloc) if not netloc_ok:return False if not CONFIG["allowed_url_pattern"].match(url_candidate if parsed.scheme else parsed.geturl()):return False for pat in CONFIG["deny_url_patterns"]:if pat.search(url_candidate): return False if CONFIG["post_url_pattern"].search(url_candidate):return True for pat in CONFIG["archive_url_patterns"]:if pat.search(url_candidate): return True return False except Exception: return Falsedef crawl(start_url: str, max_posts: int = 500, follow_links: bool = True): base = urlparse(start_url) to_visit = [start_url] visited = set() posts = [] while to_visit and len(posts) < max_posts: url = to_visit.pop(0) if url in visited:continue visited.add(url) print(f"[VISIT] {url}") try:r = fetch(url) except Exception as e:print(f"[WARN] {e}")continue post = extract_post_or_follow(url, r.text) if post:posts.append(post)print(f"[POST] {post['title']} | {post['link']}")if len(posts) >= max_posts: break if not follow_links:continue soup = BeautifulSoup(r.text, "lxml") for a in soup.find_all("a", href=True):full = urljoin(url, a["href"]).split("#")[0]if is_internal_and_allowed(base.netloc, full): if full not in visited and full not in to_visit: to_visit.append(full) time.sleep(CONFIG["sleep_sec"]) return posts# ---------------------------------# WXR builder (1.2)# ---------------------------------def rfc822(dt: datetime) -> str: return dt.strftime("%a, %d %b %Y %H:%M:%S +0000")def cdata(text: str) -> str: # split "]]>" so CDATA remains valid return "<![CDATA[" + text.replace("]]>", "]]]]><![CDATA[>") + "]]>"def export_wxr(posts: list[dict], date_bump_seconds: int = 0) -> str: now = datetime.now(timezone.utc) head = ( '<?xml version="1.0" encoding="UTF-8"?>\n' '<rss version="2.0"\n' ' xmlns:excerpt="http://wordpress.org/export/1.2/excerpt/"\n' ' xmlns:content="http://purl.org/rss/1.0/modules/content/"\n' ' xmlns:wfw="http://wellformedweb.org/CommentAPI/"\n' ' xmlns:dc="http://purl.org/dc/elements/1.1/"\n' ' xmlns:wp="http://wordpress.org/export/1.2/">\n' '<channel>\n' ' <title>Excite Export</title>\n' f' <link>{html.escape(CONFIG["base_blog_url"])}</link>\n' ' <description>Exported from ExciteBlog</description>\n' f' <pubDate>{rfc822(now)}</pubDate>\n' ' <language>ja</language>\n' ' <wp:wxr_version>1.2</wp:wxr_version>\n' f' <wp:base_site_url>{html.escape(CONFIG["base_site_url"])}</wp:base_site_url>\n' f' <wp:base_blog_url>{html.escape(CONFIG["base_blog_url"])}</wp:base_blog_url>\n' ' <generator>exblog-to-wxr</generator>\n' ' <wp:author>\n' ' <wp:author_id>1</wp:author_id>\n' f' <wp:author_login>{cdata(CONFIG["author_login"])}</wp:author_login>\n' f' <wp:author_email>{cdata(CONFIG["author_email"])}</wp:author_email>\n' f' <wp:author_display_name>{cdata(CONFIG["author_login"])}</wp:author_display_name>\n' ' <wp:author_first_name></wp:author_first_name>\n' ' <wp:author_last_name></wp:author_last_name>\n' ' </wp:author>\n' ) parts = [head] post_id = 1 for p in posts: dt_utc = p["date_utc"].astimezone(timezone.utc) if date_bump_seconds:dt_utc = dt_utc + timedelta(seconds=date_bump_seconds) post_date = dt_utc.strftime("%Y-%m-%d %H:%M:%S") parts.append(" <item>\n"f" <title>{html.escape(p['title'])}</title>\n"f" <link>{html.escape(p['link'])}</link>\n"f" <pubDate>{rfc822(dt_utc)}</pubDate>\n"f" <dc:creator>{cdata(CONFIG['author_login'])}</dc:creator>\n"f" <guid isPermaLink=\"false\">{html.escape(p['link'])}</guid>\n"f" <description></description>\n"f" <content:encoded>{cdata(p['content_html'])}</content:encoded>\n"f" <excerpt:encoded>{cdata('')}</excerpt:encoded>\n"f" <wp:post_id>{post_id}</wp:post_id>\n"f" <wp:post_date>{post_date}</wp:post_date>\n"f" <wp:post_date_gmt>{post_date}</wp:post_date_gmt>\n"f" <wp:comment_status>open</wp:comment_status>\n"f" <wp:ping_status>open</wp:ping_status>\n"f" <wp:post_name>{html.escape(p['slug'])}</wp:post_name>\n"f" <wp:status>publish</wp:status>\n"f" <wp:post_parent>0</wp:post_parent>\n"f" <wp:menu_order>0</wp:menu_order>\n"f" <wp:post_type>post</wp:post_type>\n"f" <wp:post_password></wp:post_password>\n"f" <wp:is_sticky>0</wp:is_sticky>\n"" </item>\n" ) post_id += 1 parts.append("</channel>\n</rss>\n") return "".join(parts)# ---------------------------------# CLI# ---------------------------------def main(): ap = argparse.ArgumentParser(description="ExciteBlog -> WordPress WXR exporter") ap.add_argument("--start-url", required=True, help="Start URL (e.g., https://foo.exblog.jp/ or /12345678/)") ap.add_argument("--out", default="export.xml", help="Output WXR filename") ap.add_argument("--max-posts", type=int, default=500, help="Max posts to collect") ap.add_argument("--no-crawl", action="store_true", help="Process only the start URL (no link following)") ap.add_argument("--date-bump-seconds", type=int, default=0, help="Add N seconds to every post date (avoid WP duplicate-skip)") # Optional channel fields ap.add_argument("--base-site-url", default=CONFIG["base_site_url"]) ap.add_argument("--base-blog-url", default=CONFIG["base_blog_url"]) ap.add_argument("--author-login", default=CONFIG["author_login"]) ap.add_argument("--author-email", default=CONFIG["author_email"]) args = ap.parse_args() # reflect channel overrides CONFIG["base_site_url"] = args.base_site_url CONFIG["base_blog_url"] = args.base_blog_url CONFIG["author_login"] = args.author_login CONFIG["author_email"] = args.author_email posts = crawl(args.start_url, args.max_posts, follow_links=not args.no_crawl) posts.sort(key=lambda x: x["date_utc"]) # stable order wxr = export_wxr(posts, date_bump_seconds=args.date_bump_seconds) with open(args.out, "w", encoding="utf-8", newline="\n") as f: f.write(wxr) print(f"[OK] WXR written -> {args.out} (posts: {len(posts)})")if __name__ == "__main__": main()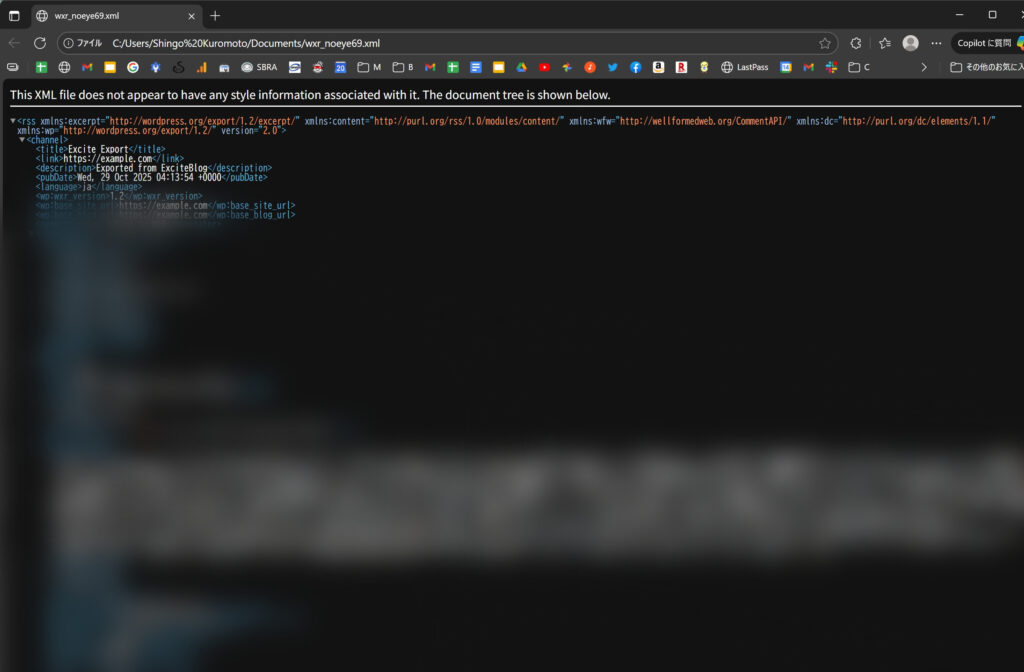
生成されたWXRファイルをワードプレスにインポートすると、数分ですべての記事がアップロードされました。神、、、!
実際には最初エキサイトブログの構造をうまく拾えなくて記事を1個も拾ってこなかったり、本文を見出し分しか拾ってこなかったりとか、多少難儀したのですが、トータル2時間くらい試行錯誤したら行けたので、やっぱりプログラミングは便利だなと思いました。手動でやってたら2,3ヶ月は掛かりそう。
カテゴリーで分けて非公開設定に
サルベージできたのはいいのですが、流石に10年以上前に書いた個人的な日記を覗かれて突かれたくないので笑、カテゴリーで分けて非公開にしました。完全に自分の思い出保管用ですね。
まとめ
あんまり直接の知り合いにブロガーはいないんですが、ネット上の色んなところに文章を書いてきて、いつかまとめたいなーと思っている人の参考になれば。




